Want a straightforward approach to prediction? Nothing is as direct as simple linear regression (SLR). Suppose that you want to predict a quantitative response variable 
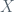

We can think of (1) as the regression of 
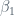




Now that we are this far, we can continue our review with some more pragmatic discussion of how to estimate the values the coefficients. To proceed, we need data; let,

represent n observations (pairs), each of which consists of a measurement of X and a measurement of Y -ultimately, we want to find a line that fits all these observations as close as possible. This idea of closeness is interesting; there are many ways we can define how close we are to the various observations, but the most common (particularly when we are talking about SLR) is least squares criterion
Consider 
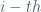

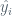
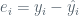
Ultimately, (4) will take us to the idea of residual sum of squares and, as we will see, the various coefficients in (2) and (1). The residual sum of squares (RSS) is direct and expressed as:
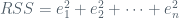
In LSR, we seek to MINIMIZE the RSS. This provides us the values of our coefficients, and hence the linear regression line.
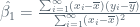
and

With 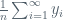

Understanding the minimization of RSS is essential, but the concept is not as straightforward as one would think. Infact, it’s easy to understand that 
So, let’s back-up. Our goal is to find a relationship that maps our observations on 

The black line is the LSR line, the red line is some other line -note that the red boxes are those that form a square from the point to the red line -the area of those squares is not minimized. That is, we never minimized the RSS to derive the correct values for our coefficients. The black boxes, however, are the areas of the squares of the LSR from each point -notice that they are minimized.
Coefficient Estimates and Accuracy
In general, LSR exhibits high interpretability and low flexibility. There are implications to model selection that must be considered; first, flexible models often require estimating a greater number of parameters and are more complex -this leads to a phenomenon known as overfitting wherein the noise is modeled too closely (the noise is integrated into the model over the signal). Second, there is the quintessential problem of spuriousness that tends to complicate all statistical models -but is more chronic amid problems where highly flexible models are more appropriate (there are methods to dealing with such a problem, but we won’t address that here). Second, there is a tradeoff that takes place amid flexibility and interpretability that is important to consider -as flexibility increases, interpretability tends to decrease.
It is important to highlight that when estimating 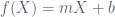

Prima facie, the idea of 
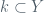

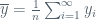
The analogy drawn above amid the sample mean and the SLR is apt based on the concept of bias. Think about it…. if we use 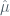
and,
Now, if we were to average these over a very large number of data sets (pulled from the same population), we would have estimates that are equal to the the “real” coefficients of the population. However, we should be asking ourselves how accurate are these estimators, when unbiased, to the population equivalents. Let’s revert back to our example of the population mean 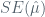

Basically, the standard error tells us the average amount that this estimate
Now, we should be able to obtain an standard error for our coefficients -so, to compute the standard error associated with 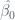



where 
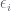

Standard errors are useful for various things; one of these is to compute confidence intervals. A 95% confidence interval (CI) is defined as a 95% probability that a range of values will contain the true unknown value of the parameter in question. The range is defined as upper and lower bounds; the 95% CI for 

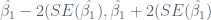
The CI states that there is approximately a 95% confidence interval that our coefficient lies within that interval. We also define the CI for our intercept (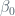

Pulling It All Together
Standard errors are more than just interesting measures to help us understand SLR. We can use these tools to perform hypothesis tests on these coefficients. We proceed as follows (some great resources here):
- Formulate a null hypothesis (think of this as the opposite of what you are guessing or looking for in your data).
- Provide an alternative hypothesis
- Set an
(this involves type 1 and 2 errors –
- Assuming you have correct data, calculate a test statistic (F, T, etc…)
- Determine thresholds of rejection.
- Derive a decision of fail to reject the null or reject the null.
