In our post on LSR, we discussed some of the basic formulas and methods to derive a linear model. Today, our goal will be to quickly review multiple linear regression, and evaluate how we interpret linear regression models.
Simple linear regression is useful, but what about situations where one has to model a significant number of variables? Suppose we have a data set that consist of three predictors and a single response variable. How should we accommodate these two new values?
Multiple linear regression is a way to accommodate additional variables, but we have to address a few concerns. Some may feel that we should proceed with creating distinct linear regression models for each predictor -and look at the goodness of the fit. The one with the best is the predictor we should go with; such an approach is insufficient, some of those predictors may have an effect on others, also its not clear, even with a best fitted predictor across models, that such is the correct one since the magnitude of the effect for what we are measuring is not denoted merely by the regression equation.
So, the best approach is to extend linear regression to multiple inputs. We can do this by giving each predictor a a separate slope coefficient in a single model. Without loss of generality, suppose we have 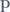

The rules still apply, however, and that means that we must estimate the coefficients of our model. Like with simple linear regression, we can proceed similarly. We make predictions by using:

The parameters are estimated using the same least squares approach that we saw in the context of simple linear regression. We choose
to minimize the sum of the squared residuals.


When considering multiple linear regression (MLR) , we should understand a few items of value. By selecting, carefully, the right variables for our model, we are able to better get a sense of the variance in the model -the variables add understanding of the variance. Moreover, we would expect, in general, that the explanatory power to increase for the model.
The pitfalls the we risk when delving into MLR are going to haunt us in many other aspects of statistical modeling, but we should be careful to watch for things like overfitting wherein we have fitted our predictors too closely; the next item is multicollinearity. Multicollinearity is a state of very high inter-correlations or inter-associations among the independent variables. It is therefore a type of disturbance in the data, and if present in the data the statistical inferences made about the data may not be reliable -another issue associated with this phenomena is spurious correlations. We may have selected predictors that correlate and, hence, are introduced into our model. However, the spuriousness of the data is actually such that we are merely modeling the noise and not the effects of the variables.
Okay, now that we got the cost and benefits out, lets keep going. We need to address a few important questions:
1) Is at least one of the predictors useful in predicting the response variable?
2) Do all the predictors help to explain Y or is only a subset of the predictors useful?
3) How well does the overall model fit the data?
Is There a Relationship Between the Response and Predictors?
In SLR, we can merely verify whether 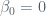

Challenged by the alternative

To test the hypothesis, we will compute the F-statistic,

So, when the F-statistic takes on a value close to 1, we would have no relationship amid the response and predictors.
Do all The Predictors Explain Help to Explain Y?
We have to understand that the regression plane, or the MLR, is merely an estimator for the true regression plane across our predictors. Hence, there is error involved in our model. The same thing goes for SLR, and the accuracy or, otherwise, the inaccuracy of the coefficient estimates is related to the reducible error; thus, we can compute the confidence interval in order to determine how close 
We do not remove, in our efforts at estimating reality using a linear model, potential reducible error -or, model bias. Nonetheless, even if we knew the true values for the predictors, the response variable cannot be predicted perfectly because of random error 
Here is a source of some more information, along with a video: LINK
